
1·
5 days agoI can dig it. I love layered wordplay in any language.
I can dig it. I love layered wordplay in any language.

I guess those scientist guys all working on A.I. never gave cocaine and Monster Energy a try.
Fun Fact: Artax can speak in the novel.

Ctrl+f “attractor state” to find the section. They named it “spiritual bliss.”
DeepMind keeps trying to build a model architecture that can continue to learn after training, first with the Titans paper and most recently with Nested Learning. It’s promising research, but they have yet to scale their “HOPE” model to larger sizes. And with as much incentive as there is to hype this stuff, I’ll believe it when I see it.
Everyone seems to be tracking on the causes of similarity in training sets (and that’s the main reason), so I’ll offer a few other factors. System prompts use similar sections for post-training alignment. Once something has proven useful, some version of it ends up in every model’s system prompt.
Another possibility is that there are features of the semantic space of language itself that act as attractors. They demonstrated and poorly named an ontological attractor state in the Claude model card that is commonly reported in other models.
If the temperature of the model is set low, it is less likely to generate a nonsense response, but it also makes it less likely to come up with an interesting or original name. Models tend to be mid/low temp by default, though there’s some work being done on dynamic temperature.
The tokenization process probably has some effect for cases like naming in particular, since common names like Jennifer are a single token, something like Anderson is 2 tokens, and a more unique name would need to combine more tokens in ways that are probably less likely.
Quantization decreases lexical diversty, and is relatively uniform across models. Though not all models are quantized. Similarities in RLHF implementation probably also have an effect.
And then there’s prompt variety. There may be enough similarity in the way in which a question/prompt is usually worded that the range of responses is restrained. Some models will give more interesting responses if the prompt barely makes sense or is in 31337 5P34K, a common method to get around alignment.

Simpsons did it.
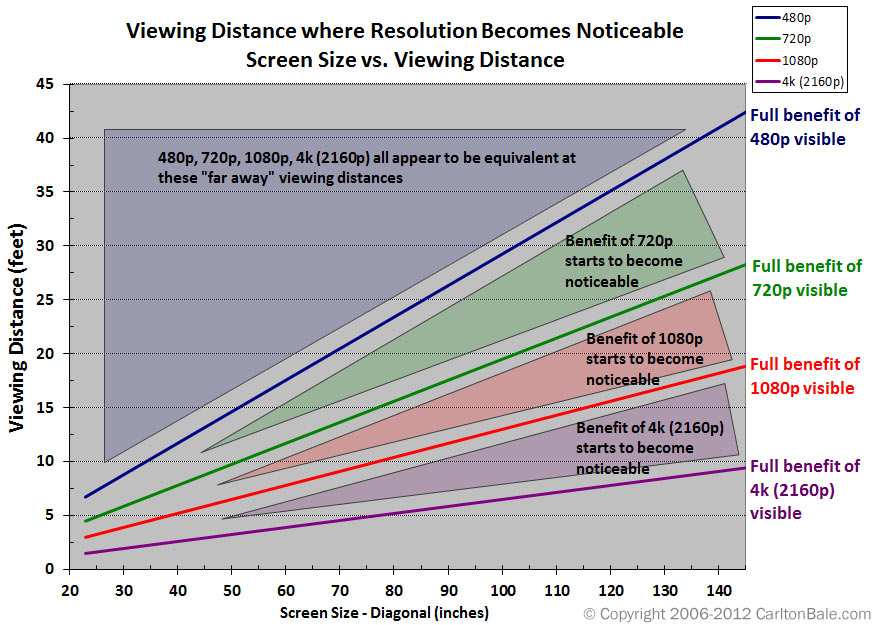
I can pretty confidently say that 4k is noticeable if you’re sitting close to a big tv. I don’t know that 8k would ever really be noticeable, unless the screen is strapped to your face, a la VR. For most cases, 1080p is fine, and there are other factors that start to matter way more than resolution after HD. Bit-rate, compression type, dynamic range, etc.

The fact that workers with expense accounts still feel they’re getting paid so little that they deserve to commit fraud says something about that stratum of employee.
Pretty much anyone who travels has to submit receipts. Most people who travel are not making bank. They’re the people who set up and stand at convention booths, sales staff support, assistants, videographers, etc. Also, most travel is a miserable ordeal. I’m not saying it’s okay to commit fraud, but let’s not equate the hourly employee “re-creating” his lost lunch receipt with a 6-figure income.

Cyberpunk 2077

This is kinda the plot of Hudson Hawk.
Hey! An excuse to quote my namesake.
Hackworth got all the news that was appropriate to his situation in life, plus a few optional services: the latest from his favorite cartoonists and columnists around the world; the clippings on various peculiar crackpot subjects forwarded to him by his father […] A gentleman of higher rank and more far-reaching responsibilities would probably get different information written in a different way, and the top stratum of New Chuasan actually got the Times on paper, printed out by a big antique press […] Now nanotechnology had made nearly anything possible, and so the cultural role in deciding what should be done with it had become far more important than imagining what could be done with it. One of the insights of the Victorian Revivial was that it was not necessarily a good thing for everyone to read a completely different newspaper in the morning; so the higher one rose in society, the more similar one’s Times became to one’s peers’. - The Diamond Age by Neal Stephenson (1995)
That is to say, I agree that everyone getting different answers is an issue, and it’s been a growing problem for decades. AI’s turbo-charged it, for sure. If I want, I can just have it yes-man me all day long.
Eh, people said the exact same thing about Wikipedia in the early 2000’s. A group of randos on the internet is going to “crowd source” truth? Absurd! And the answer to that was always, “You can check the source to make sure it says what they say it says.” If you’re still checking Wikipedia sources, then you’re going to check the sources AI provides as well. All that changes about the process is how you get the list of primary sources. I don’t mind AI as a method of finding sources.
The greater issue is that people rarely check primary sources. And even when they do, the general level of education needed to read and understand those sources is a somewhat high bar. And the even greater issue is that AI-generated half-truths are currently mucking up primary sources. Add to that intentional falsehoods from governments and corporations, and it already seems significantly more difficult to get to the real data on anything post-2020.

Rogue Legacy 2, if it counts. Otherwise, Axiom Verge.