- 8 Posts
- 202 Comments




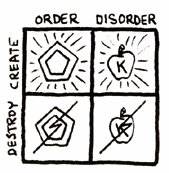
To choose order over disorder, or disorder over order, is to accept a trip composed of both the creative and the destructive. But to choose the creative over the destructive is an all-creative trip composed of both order and disorder. To accomplish this, one need only accept creative disorder along with, and equal to, creative order, and also willing to reject destructive order as an undesirable equal to destructive disorder.
The Curse of Greyface included the division of life into order/disorder as the essential positive/negative polarity, instead of building a game foundation with creative/destructive as the essential positive/negative. He has thereby caused man to endure the destructive aspects of order and has prevented man from effectively participating in the creative uses of disorder. Civilization reflects this unfortunate division.
THE CURSE OF GREYFACE AND THE INTRODUCTION OF NEGATIVISM - Principia Discordia

Have you tried video editing? You can do a lot with a good song and curiosity.


 3·16 days ago
3·16 days agoHop on Adobe stock right now and search for something. Half of the results will be AI-generated. There’s a search filter that can exclude them.
 8·16 days ago
8·16 days agoI’m an editor by trade, and weirdly, I think Acolyte’s main problem is editing. When I later heard that the story was supposed to be all about the Sith and was reworked by producers, it clicked. It’s cut like someone doing their best to make a story make sense after cornerstones of that story are removed. I’ve been in that position. It sucks.
That’s neat, I hadn’t heard about this show. The trailer looks fun. Is it just me, or does Jaleel look rendered in this shot?
 4·20 days ago
4·20 days agoI think this is accurate. But I’d like to restate it.
The Left (as the apparent big tent party full of literal minorities) has been learning to deal with disenfranchisement and the feeling “that their anguish is belittled as a personal failure, and often downright mocked” for its entire existence. Because of a huge variety of factors, the Right is losing some of its influence. They are not handling this well. The Left (being well acquainted with feeling unheard) should have been able to help the Right through this transition. Due to deep seated insecurities on both sides, we are no longer able to help one another as a people. Buckle up.


deleted by creator
 32·27 days ago
32·27 days agoCalling what attention transformers do memorization is wildly inaccurate.
*Unless we’re talking about semantic memory.
It honestly blows my mind that people look at a neutral network that’s even capable of recreating short works it was trained on without having access to that text during generation… and choose to focus on IP law.
The issue is that next to the transformed output, the not-transformed input is being in use in a commercial product.
Are you only talking about the word repetition glitch?
How do you imagine those works are used?
It’s called learning, and I wish people did more of it.
This is an inaccurate understanding of what’s going on. Under the hood is a neutral network with weights and biases, not a database of copyrighted work. That neutral network was trained on a HEAVILY filtered training set (as mentioned above, 45 terabytes was reduced to 570 GB for GPT3). Getting it to bug out and generate full sections of training data from its neutral network is a fun parlor trick, but you’re not going to use it to pirate a book. People do that the old fashioned way by just adding type:pdf to their common web search.
You’ve made a lot of confident assertions without supporting them. Just like an LLM! :)
Just taking GPT 3 as an example, its training set was 45 terabytes, yes. But that set was filtered and processed down to about 570 GB. GPT 3 was only actually trained on that 570 GB. The model itself is about 700 GB. Much of the generalized intelligence of an LLM comes from abstraction to other contexts.
Table 2.2 shows the final mixture of datasets that we used in training. The CommonCrawl data was downloaded from 41 shards of monthly CommonCrawl covering 2016 to 2019, constituting 45TB of compressed plaintext before filtering and 570GB after filtering, roughly equivalent to 400 billion byte-pair-encoded tokens. Language Models are Few-Shot Learners
*Did some more looking, and that model size estimate assumes 32 bit float. It’s actually 16 bit, so the model size is 350GB… technically some compression after all!
deleted by creator

{kind=link}
{kind=link}
deleted by creator